 钟声博客
钟声博客说明
朋友让我写一个爬虫,他要学习一下,其实我也不会啊,好久以前了解过Python,但从来没有动手写过呀。Python是一门非常优秀的语言,我打算以后要深入学习的,但既然朋友开口了,不如现在就体验一下。简单地看了一遍Python的语法,便带上手册,便出发了。
准备
要爬的网站是图虫网,这是一个高质量的图片社区,聚集着一群年轻的摄影爱好者。
工具:python 2.7,BeautifulSoup4
注意:BeautifulSoup4为第三方类库,如果在cmd下用pip安装报错,可直接去官网下载,解压后拷贝到python安装目录中的lib目录下,通过cmd进入插件的目录,输入python setup.py install,即可安装。
分析
爬虫的人口页为: https://tuchong.com/explore/

可以看到这页的每张图片都代表一个题材,点进去后就是这个题材下所有的相册,如下图。

打开相册后发现相册里的图片都是用js加载的,面对这种情况可以自己分析js,用Request发送请求获取数据。也可以用一些模拟js行为的库来抓取数据,但这样对cpu和内存的消耗会增大,抓取速度也很慢,如非必要建议不使用。
以下是爬虫的核心代码,先解析出所有题材的url地址,然后爬虫循环爬取每个题材的封面照片,因为只是想写一个最小化的爬虫,所以涉及js的部分我们就不探讨了。
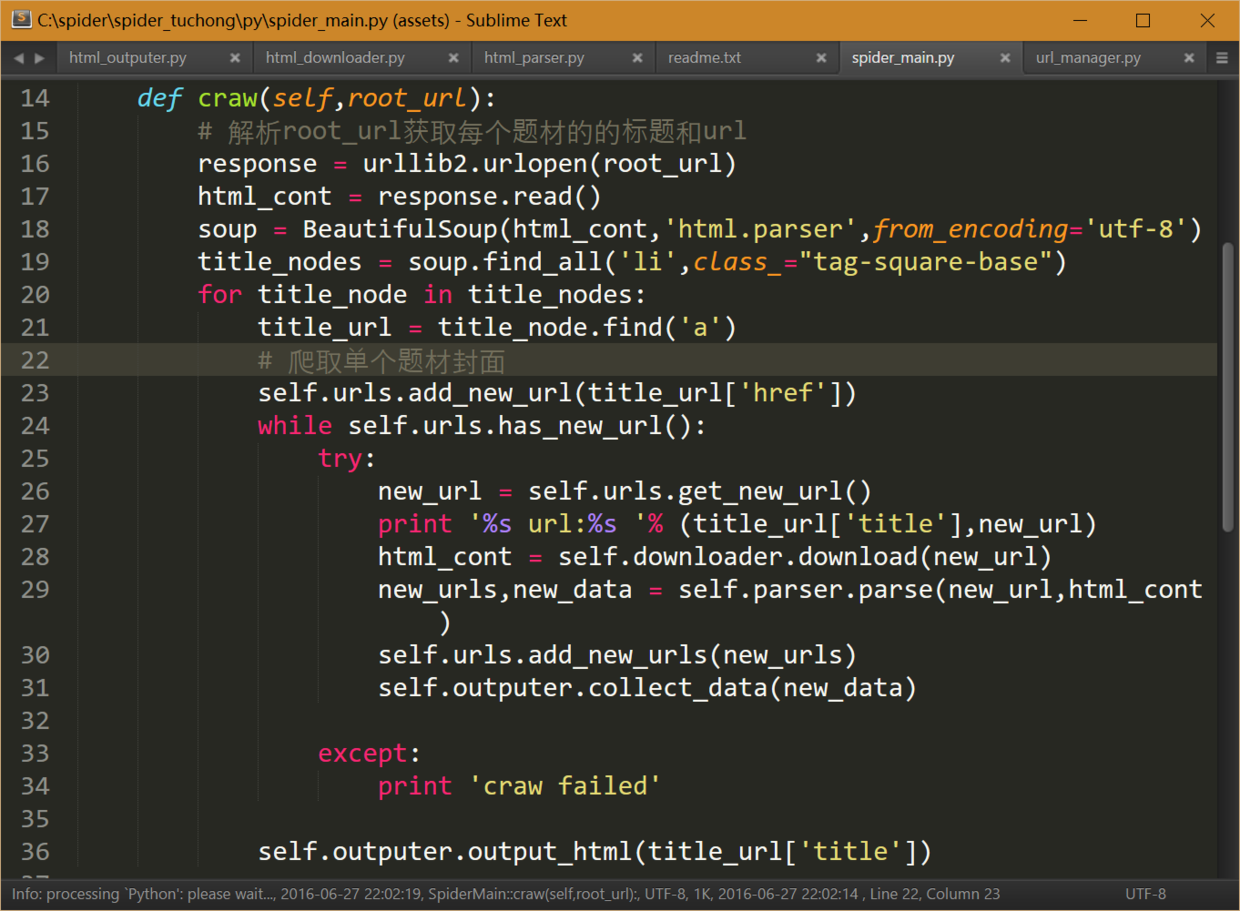
运行
下面让我们的爬虫跑起来,我运行在了服务器上了,大家可以直接通过浏览器访问爬取的结果。
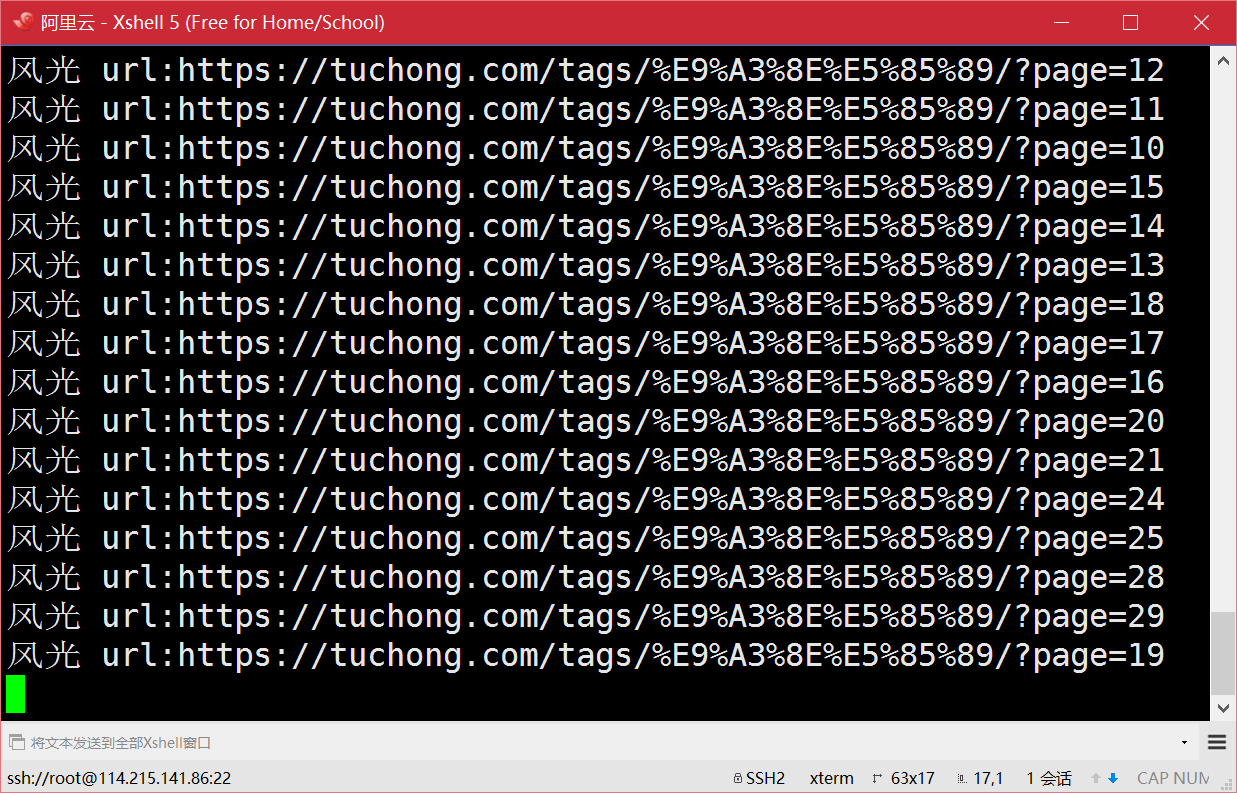

一段时间后运行完毕,打开生成的page文件夹,看到爬虫为我们生成的html页面,可以通过下面这个url访问 (ps: 每个网页大约50M,流量党慎入。)
http://114.215.141.86/zs/spider/page/%E5%B0%91%E5%A5%B3.html

最后
这个网站很简单,不需要登录验证码,连请求头都不用写,爬虫也没有写的太暴力,只是保存了图片的url地址,并没有抓取到本地,别对人家服务器造成压力麻。
给大家推荐几个学习爬虫的教程:
幕课网开发简单爬虫: http://www.imooc.com/learn/563
幕课爬虫Github地址:https://github.com/zhongsheng23/spider_baidubaike.git
爬虫学习的系列教程: http://cuiqingcai.com/1052.html
文章爬虫Github地址:https://github.com/zhongsheng23/spider_tuchong.git
反爬虫策略浅析:http://robbinfan.com/blog/11/anti-crawler-strategy
第一个Python程序,写的很乱,他估计也没法看,写完后我自己都有删代码的冲动了,如果代码哪里不合理,麻烦大家指正啊。此程序只作学习之用,如果有什么不合适的地方,请告知!